

RAM is scarce on phones, and LLMs are big fans of RAM.
After artificial intelligence overtook the metaverse as the internet’s cause célèbre last year, big tech has seen radical changes. People are suddenly building their own large language models (LLMs), but the majority of them require powerful server hardware running in the cloud. Smartphones lack the memory to run the largest, most capable models, but Apple engineers believe they have found a workaround: in a recent research paper, they suggest keeping LLM parameters on the iPhone’s NAND flash instead of its RAM-deficient RAM.
Your next device may be able to run a local AI thanks to Qualcomm, Intel, and other companies adding machine learning hardware to their most recent chips. The issue is that big language models can be quite large, requiring trillions of parameters to reside in memory at all times, and phones—especially Apple phones, which have a maximum RAM of just 8GB in the iPhone 15 Pro—do not have a lot of RAM.
These models’ AI accelerator cards in data centers have significantly more memory than comparable graphics cards—for instance, the Nvidia H100 has 80GB of HBM2e memory, whereas the gaming-oriented RTX 4090 Ti has only 24GB of GDDR6X.
Apple’s latest research aims to fit a larger model into a smartphone by relying on the NAND flash storage, which is usually at least 10 times larger than the phone’s RAM. The main problem is speed—flash storage is much, much slower. Google is working toward enhanced mobile LLMs with its new Gemini model, which features a “nano” version intended for smartphones.
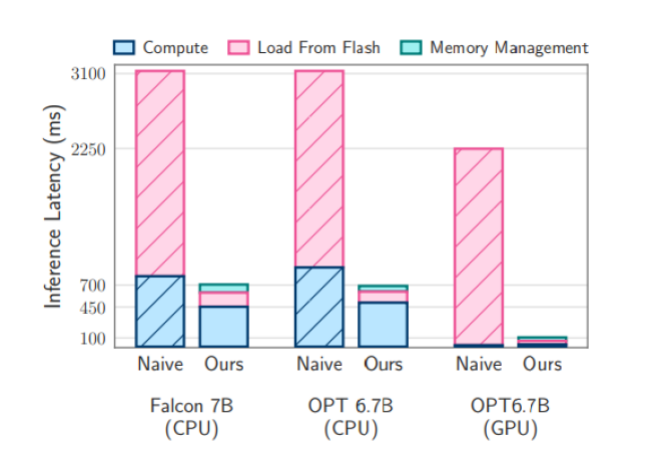
The study found that the team employed two strategies to run their model without RAM, both of which are meant to minimize the amount of data the model needs to load from storage: row-column bundling was also used to group data more effectively so the model could process larger data chunks; windowing permits the model to load parameters for only the last few tokens, essentially recycling data to reduce storage access time.
The study concludes that this approach could pave the way for running LLMs on devices with limited memory. The research was successful in increasing the LLM capabilities of the iPhone. Using this approach, LLMs run 4-5 times faster on standard CPUs and 20-25 times faster on GPUs. Perhaps most importantly, the iPhone can run AI models twice the size of its installed RAM by keeping the parameters on the internal storage.